Exploring AI and ML
Learn, Build, Deploy
2023-12-31
If you want to learn more about Machine Learning and AI in Dayton, please attend a GemCity Machine Learning meetup.
GemCity ML/AI
We meet every third Thursday at 6pm as part of GemCity Tech meetup group.
GemCity.TECH
GemCity TECH’s mission is to grow the local industry and the community by providing a centralized destination for technical training, workshops and providing a forum for collaborating.
Currently, support several special interest groups from a variety of technical disciplines.


What is AI and ML?
Artificial Intelligence (AI)
- A field in computer science
- AI is something that has the ability “learn” to do something without instructions.
Machine Learning (ML)
- Machine learning is a field of study in artificial intelligence
- ML uses statistical algorithms that can learn from data and generalize to unseen data (Testing/User data)
- Perform tasks without explicit instructions.
Example of Data for Supervised Learning
| Data | Truth (Label) | Data | Truth (Label) |
|---|---|---|---|
 |
cat |  |
dog |
x 100’s more Labeled images
Example of data for unsupervised learning
| Data | Data |
|---|---|
|
|
x 500’s more images
Gedunken Experiment
Say there is a town with two employers (A and B).
Predict if person works for company A or B, based on where they live.
First stab: See if people are clustered around their work place.
So if we had a clustering algorithm we can predict where a person might work.
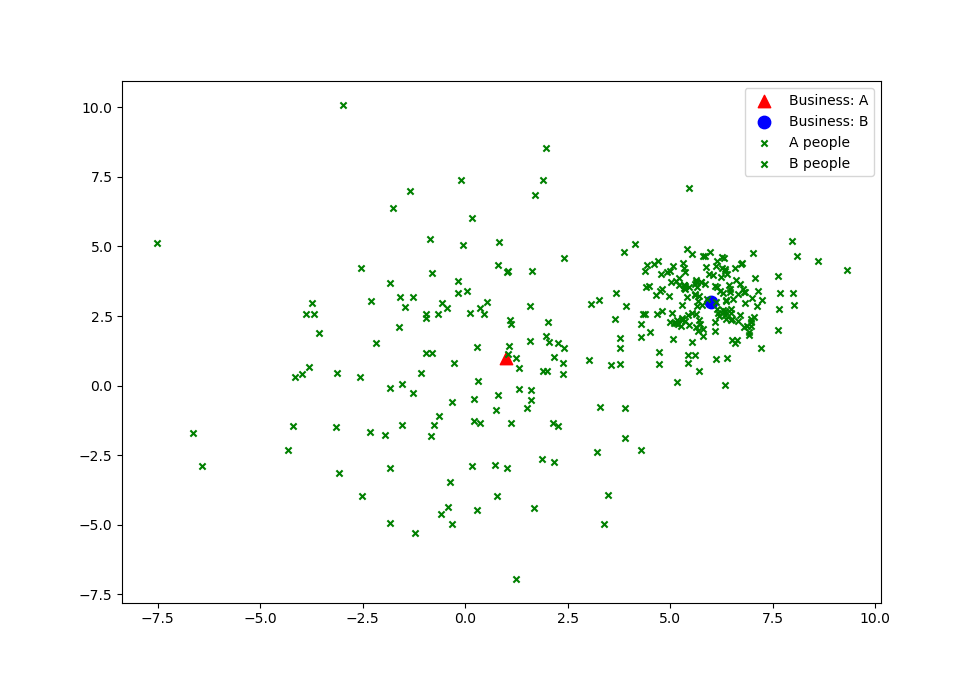
K-Means
K-means is the most common clustering algorithm.
K-means clusters, n data points (e.g. All your data) into k clusters by placing each data point to the nearest k.
Example: point p is 5 ft from \(k_i\) and 10 feet from \(k_j\). K-means would then place point p into the \(k_i\) group. Once, all the points are placed into a cluster or group, the new means for each cluster (\(k_i\) and \(k_j\)) are updated. The location for each mean cluster k is calculated by finding the mean from all the points that belong to that cluster.

Transfer Learning
Transfer Learning can allow you to use what is learned from a large dataset to your smaller (refined) data similar to the larger model.
Sarkar (2018)
- Example: ImageNet Dataset has 1.4 million images and 1000 classes.
To learn more go to TensorFlow Transfer Learning Tutorial
Classification
Say you are tasked to group monkeys into two classes:
- Class_1: Biting Monkey
- Class_2: Non-Biting Monkeys
Developing a Model
- Create a rule to define: Biting and NonBiting
- Separate your monkeys by that rule
- Repeat until all of your monkeys can follow your rule.

Image from Huffington Post.
| Class_1: Biting | Class_2: Non Biting |
|---|---|
| card c | card d |
| card a | card b |
| … | … |
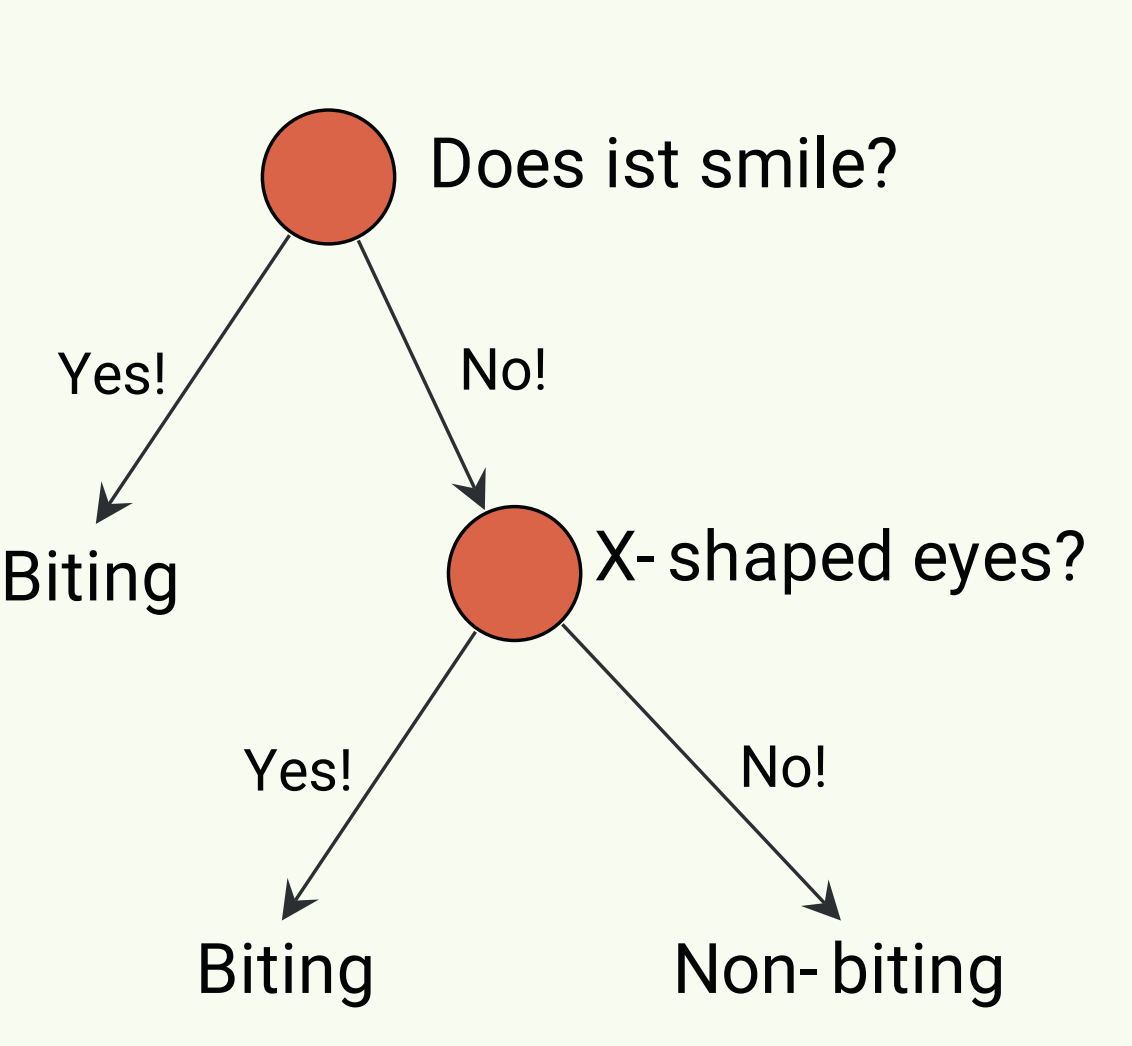
Classification Model: Evaluation
What Rule did you use to determine which class the Monkey belongs to?
Does your model hold up?
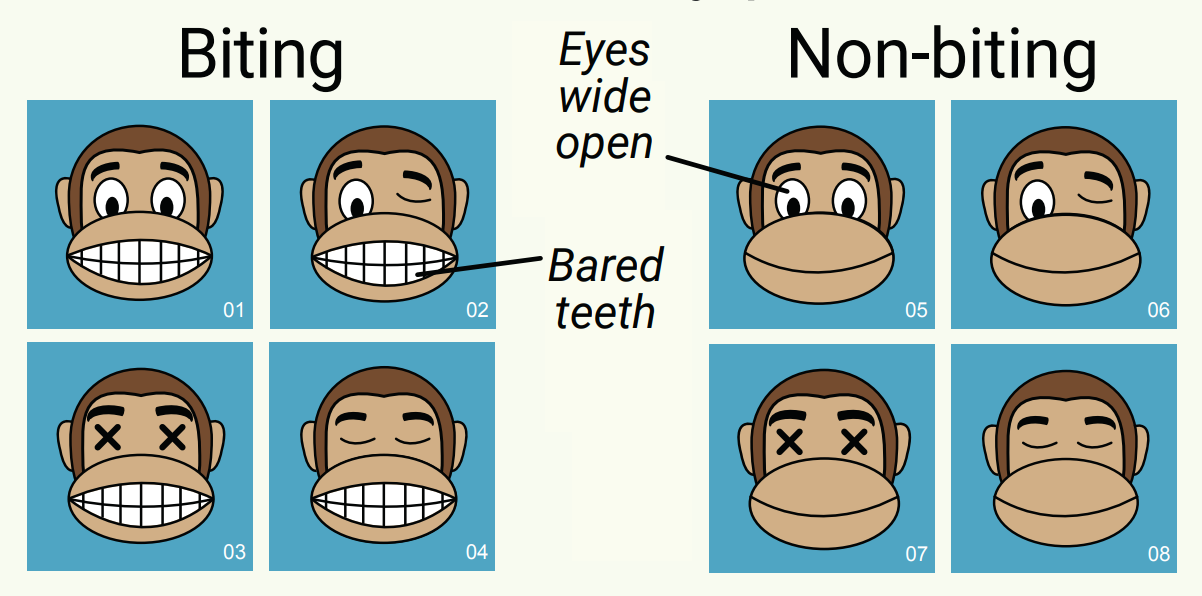
- Class_1= Biting Monkey
- Class_2= Non-Biting Monkeys
Building a ML Model
There are four basic steps to building a model
- Train the model
- Export the model
- Use the model
- Forth Step: Repeat
Why a forth step
Your model, app etc will not work the first time.

Training a model to classify sounds
We are going to train a ML model to classify sounds.
WITHOUT any coding.
- Google “Teachable Machine”
- Click Get Started
- Click Audio Project (standard model)
- Create three classes:
- Background
- Clapping
- Snapping

Thank you
If you want to take this to the classroom.
I have a No Code ML Tutorial for Elementary School Children
- Train a model to classify hand gestures
- Learn what a classifier is
- Use conditional statements to turn those classes into an emoji
- Build a Web application

References
